
파이썬으로 배우는 포트폴리오 study day6
2022.11.30 - [TIL/09_QUANT] - [퀀트] 평균-분산 포트폴리오 이론 (1)
2022.12.01 - [TIL/09_QUANT] - [퀀트] 평균-분산 포트폴리오 이론 (2)
이어서 3편
평균-분산 포트폴리오 이론 3
무위험자산과 최적 자산배분
무위험자산 + 위험자산 + 효율적 투자선(자본배분선)
자본배분선 (capital allocation line : CAL)
- 무위험자산이 존재하는 경우의 효율적 투자선
- 자본배분선의 기울기는 위험 한 단위당 보상되는 수익률을 나타낸 것
- = 위험보상비율 = 초과수익률 / 위험크기
$$
E(r_p) = r_f + [\frac{E(r_p) - r_f}{\sigma_T}]\sigma_P
$$
- 포트폴리오 T : 모든 위험 포트폴리오 중 위험보상비율이 가장 큰 포트폴리오
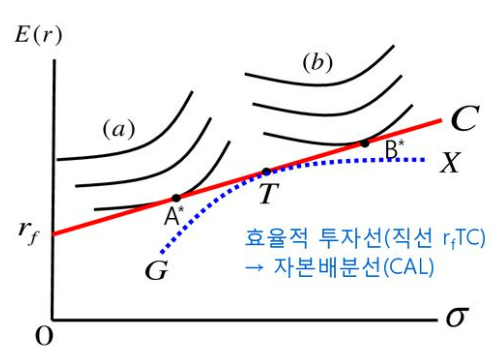
위 그림에서 $r_fTC$는 다른 모든 포트폴리오를 지배하고 있다고 표현하며,
이때 포트폴리오 T를 접점포트폴리오 (tangent portfolio) 라고 한다.
이 포트폴리오는 효율적 투자선상 포트폴리오 중에서도 가장 우월한 포트폴리오다.
그리고 전의 포스팅에서 잠깐 나왔던 내용인데, $r_fTC$는 자본배분선(Capital Allocation Line, CAL) 라고 한다.
즉, 무위험자산이 존재하는 경우 이 자본배분선이 효율적 투자선이 되는 것이다.
2022.12.01 - [TIL/09_QUANT] - [퀀트] 평균-분산 포트폴리오 이론 (2)
[퀀트] 평균-분산 포트폴리오 이론 (2)
파이썬으로 배우는 포트폴리오 study day5 2022.11.30 - [TIL/09_QUANT] - [퀀트] 평균-분산 포트폴리오 이론 (1) 에 이어서 계속!! 평균-분산 포트폴리오 이론 2 최소분산포트폴리오 저번 편에서 구한 포트폴
joo-code.tistory.com
위 포스팅에서 포트폴리오 기대수익률 식을 구했었다.
$$
E(r_P) = r_f + \frac{[E(r_i) - r_f]}{\sigma_i} \sigma_P
$$
무위험자산이 있는 포트폴리오 기대수익률 $E(r_P)$와 포트폴리오 위험 $sigma_P$ 간의 선형관계를 나타낸 식이었다.
이번에는 $r_fTC$ 이 자본배분선을 구해보면
$$
E(r) = r_f + \frac{[E(r_P) - r_f]}{\sigma_P} \sigma
$$
(책과 동일하게 나타내기 위해 $r_fTC$의 T를 P로 나타낸 것)
기울기에 해당하는 $\frac{[E(r_P) - r_f]}{\sigma_P}$ 는 수익률을 위험으로 나눈 것이다.
즉, 위험 한 단위를 부담하는 대신 얻을 수 있는 수익률. 이를 위험보상비율이라고 함
최적 포트폴리오 선택
1단계 : 지배원리에 따라 전체투자기회집합에서 효율적 투자선을 찾아낸다.
2단계 : 투자자의 기대효율을 극대화하고자 투자자의 위험회피 성향을 보여주는 무차별곡선과 효율적 투자선이 접하는 최적 포트폴리오를 찾아낸다. 이를 포트폴리오 분리 정리(protfolio separation theorem)라 한다.
- 무위험자산이 없는 경우
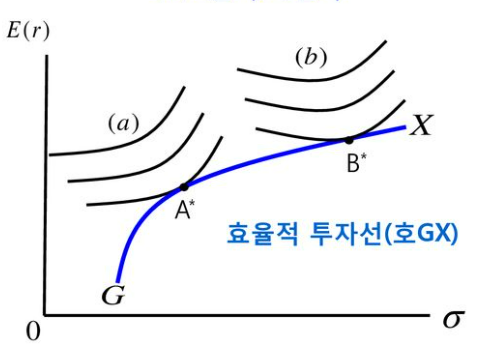
위험회피성향이 강한 투자자 a는 포트폴리오 A를 선택함으로써 기대효용 극대화
위험회피성향이 약한 투자자 b는 포트포리오 B를 선택함으로써 기대효용 극대화
즉, 투자자 a가 b보다 상대적으로 위험을 더 싫어한다고 볼 수 있다. 투자자 a 가 더 보수적
또한 상대적으로 위쪽에 있는 곡선일 수록 더 높은 효용을 나타낸다.
- 무위험자산이 있는 경우
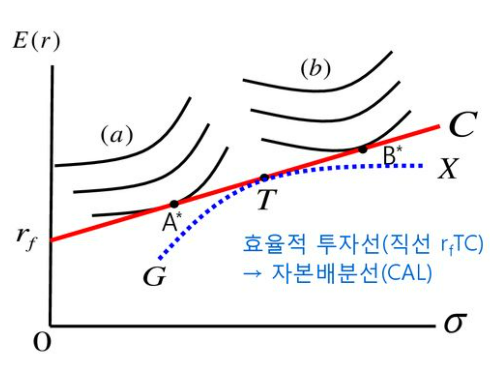
최적포트폴리오는 투자자 위험회피성향에 따라 자본배분선이 다르다.
그러나 투자자 성향과 관계없이 위험자산은 접점포트폴리오에만 투자한다.
위험을 회피하려는 성향을 가진 투자자 a는 A가 최적 포트폴리오이며, 투자 자금의 일부는 무위험자산에 투자하고 나머지는 접점포트폴리오 T에 투자할 것이다.
반면에 공격적인 투자 성향을 가진 투자자 b는 B가 최적 포트폴리오이며, 무위험이자율 $r_f$로 자금을 빌려 T를 투자한다.
즉, 위험회피성향의 차이에 따라 접점포트폴리오(T)와 무위험자산의 구성비율만 다를 뿐, 최적포트폴리오에서 위험자산의 상대적 구성비율은 접점포트폴리오(T)의 구성비율과 동일하다.
무차별곡선
무차별곡선은 미시경제학에서 나오는 용어인데, 경제주체가 동일한 효용을 제공하는 재화들의 조합을 연결한 곡선이다.
효용(재화가 가져다주는 만족감)을 측정할 수는 없지만 어느 하나의 재화만 편애하지 않고 차별없이 같은 효용을 느끼는 곡선
효율적 투자선 PYTHON CODE
다섯 개 주식의 1년치 수정주가를 가지고 비중을 달리하는 수만 개의 포트폴리오를 만들어 효율적 투자선을 구하는 실습을 해보자.
아래 실습은 몬테카를로 시뮬레이션을 바탕으로 하며 책에 있는 내용에서 샤프 지수를 추가하여 조금 더 내용을 더했다.
몬테카를로 시뮬레이션
무작위 추출된 난수를 이용하여 모델(함수)을 구하는 알고리즘
1. 라이브러리 호출
import numpy as np
import pandas as pd
from pandas_datareader import data as web
import matplotlib.pyplot as plt
import matplotlib as mpl
2. 종목과 주가 데이터 불러오기
# 다섯 개 종목(애플, 페이스북, 아마존, 제너럴일렉트릭, 테슬라)를 가지고
# 비중을 무수히 바꿔 포트폴리오를 만든다.
tickers = ['AAPL','F','AMZN','GE','TSLA']
# 수정주가를 저장할 데이터프레임 변수(adjClose)를 미리 만들어둔다.
pxclose = pd.DataFrame()
# for 루프로 다섯 개 종목을 반복하면서 반복 중에 pandas.datareader를 이용해
# 야후 파이낸스에서 일간 주거 데이터를 가져온다.
for t in tickers:
pxclose[t] = web.DataReader(t, data_source='yahoo', start='01-12-2021', end='01-12-2022')['Adj Close']
pxclose
3. 종가 수익률 계산
# 종가의 수익률 계산
ret_daily = pxclose.pct_change()
## 종가수익률 벡터
### (당일 종가 가격-전일 종가 가격)/전일 종가 가격 = 판다스의 pct_change() 메서드
# 종가수익률 평균에 252(1년 중 시장이 열리는 일수)을 곱해 기대수익률을 만든다.
ret_annual = ret_daily.mean() * 252
# 일간수익률의 공분산을 계산하고 연간 단위로 만든다.
cov_daily = ret_daily.cov()
cov_annual = cov_daily * 252ret_annual
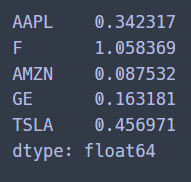
cov_annual

4. 포트폴리오 기대수익률, 변동성, 투자 비중, 샤프 지수 계산
# 포트폴리오 수익률, 변동성, 투자 비중, 샤프지수를 저장할 변수를 미리 준비
p_returns = []
p_volatility = []
p_weights = []
sharpe_ratio = []
# len() 함수로 투자자산의 수를 계산한다.
n_assets = len(tickers)
# 다섯 개 종목으로 투자 비중을 바꿔 3만 개의 포트폴리오를 만든다.
n_ports = 30000
# n_ports만큼 반복하면서 자산의 투자 비중을 랜덤하게 만들고 포트폴리오의 기대수익률, 변동성, 샤프지수 계산
# 계산한 수익률, 변동성, 투자 비중, 샤프지수를 앞서 미리 준비한 변수, p_returns, p_volatility, p_weights, sharpe_ratio에 저장
for s in range(n_ports):
wgt = np.random.random(n_assets) # 난수 생성
# 투자 비중 합계 100%를 위해 각 난수를 난수 합으로 나눈다.
wgt /= np.sum(wgt)
# 투자 비중 * 기대수익률로 기대수익률 계산 𝐸(𝑟_i)
# 종목 비율(가중치) 리스트와 연간 수익률 리스트의 내적곱
ret = np.dot(wgt.T, ret_annual)
# 변동성 계산 = \sigma (𝜎)
# w * sigma_i^2 * w
# (종목비율)((종목별 연간 공분산)(종목비율))의 행렬 내적곱 계산 후 제곱근
vol = np.sqrt(np.dot(wgt.T, np.dot(cov_annual, wgt)))
# 계산한 수익률 추가 𝐸(𝑟)
p_returns.append(ret)
# 변동성 추가 𝜎
p_volatility.append(vol)
# 투자 비중 추가 𝑤
p_weights.append(wgt)
# 샤프 지수 추가
# (수익률 - 무위험수익률) / 표준편차(리스크)
sharpe_ratio.append(ret / vol)
print(len(p_returns))
print(len(p_volatility))
print(len(sharpe_ratio))
# >> 30000
# >> 30000
# >> 30000
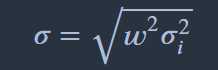
참고로 위 식 구할 때 바로 wgt^2 x cov_annual 하지 않은 이유

이렇게 배열로 나옴..
그래서
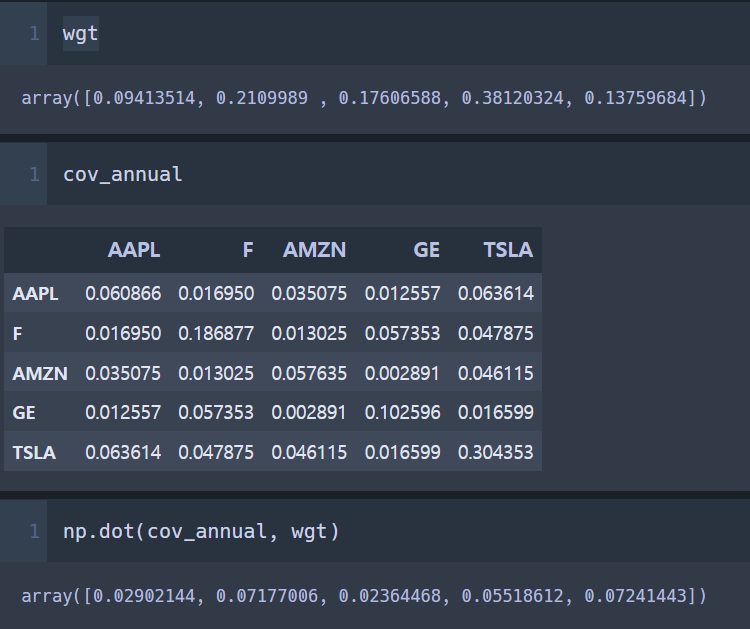
이렇게 배열로 만들어 준 다음
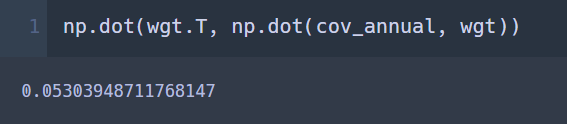
전치 시킨 wgt를 내적곱 다시 해줘서 스칼라 값으로 나오게 한 것
5. 샤프지수가 가장 큰 행 리스크가 가장 작은 행
# 데이터프레임에 저장
port_df = pd.DataFrame({"Returns":p_returns, "Risk":p_volatility, "Sharpe":sharpe_ratio})
# 각 포트폴리오의 종목 비율을 데이터프레임에 저장
for i, t in enumerate(tickers):
port_df[t] = [w[i] for w in p_weights]
# 샤프지수가 가장 큰 데이터프레임 행 변수 저장
max_sharpe = port_df[port_df['Sharpe'] == port_df['Sharpe'].max()]
# 리스크가 가장 적은 데이터프레임 행 변수 저장
min_risk = port_df[port_df['Risk'] == port_df['Risk'].min()]
- 연간 수익률 75.5%, 리스크(표준편차) 28.9%, 애플 34.3%, 페이스북 57.4%, 아마존 0.9%, 제너럴일렉트릭 1.4% 테슬라 5.8% 가량의 비율을 가지고 있는 포트폴리오, 샤프지수는 2.6
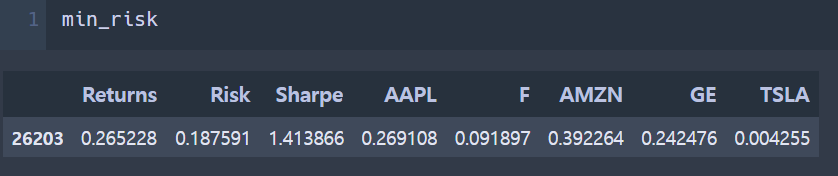
- 연간 수익률 22.6%, 리스크(표준편차) 18.7%, 애플 26.3%, 페이스북 5%, 아마존 38.8%, 제너럴일렉트릭 29.6% 테슬라 0.1% 가량의 비율을 가지고 있는 포트폴리오, 샤프지수는 1.2
☞ 리스크를 줄이기 위해서는 페이스북 비중을 줄이고 아마존, 제너럴일렉트릭 비중이 높아야 한다.
6. 시각화
# 색상을 n_ports만큼 만든다.
colors = np.random.randint(0, n_ports, n_ports)
plt.style.use('seaborn-poster')
port_df.plot.scatter(x='Risk', y='Returns', c=colors)
# max_sharpe 행을 * 표시
plt.scatter(x=max_sharpe['Risk'], y=max_sharpe['Returns'], c='r', marker='*', s= 200)
# min_risk 행을 o마커로 표시
plt.scatter(x=min_risk['Risk'], y=min_risk['Returns'], c='r', marker='o', s= 200)
# x축 라벨
plt.xlabel('Volatility(Std. Devation)')
# y축 라벨
plt.ylabel('Expected Returns')
# 차트 제목
plt.title('Efficient Frontier')
plt.show()
위 그림에서 별 표시 부분이 샤프 지수가 최대인 부분, 동그라미 표시 부분이 리스크가 최저인 부분이다.
그리고 산점도에서 맨 위 호를 그리는 부분이 효율적 투자선!
이 선 안에 있는 포트폴리오 점들은 더 이상 리스크를 줄이거나 수익률을 증가시킬 여지가 없는 효율적인 포트폴리오라고 할 수 있다.
참고자료
https://slidesplayer.org/slide/13989525/