
파이썬으로 배우는 포트폴리오 study day4
평균-분산 포트폴리오 이론
'포트폴리오 선택'에서 마코위츠는 수익의 분산을 통해 투자 리스크를 수치화했다.
분산 포트폴리오 수익은 개별 주식의 평균 수익률과 같아도 그 변동성(분산이자 리스크)은 개별 주식의 그것보다 줄어든다.
평균-분산 포트폴리오 이론 가정
- 모든 투자자의 투자 기간은 1 기간이다.
- 투자자는 위험을 회피하고 기대효용을 극대화하려 한다.
- 기대수익률과 표준편차에 따라 투자를 결정하며, 지배원리에 따라 투자 대상을 선택한다.
- 거래비용과 세금은 없으며, 모든 투자자는 무위험이자율로 한도 없는 차입과 대출을 할 수 있다.
포트폴리오 기대수익률과 위험
투자기회집합
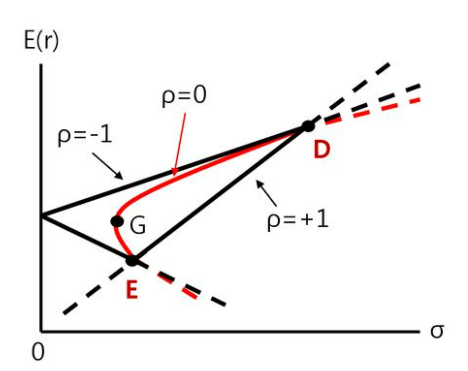
E(r)은 포트폴리오의 대수익률, $\sigma$는 포트폴리오 수익률의 분산, $\rho$는 상관계수
위험을 줄이면서 수익률을 높이기 위해 마코위츠는 상관계수가 낮은 자산을 결합해 최적 포트폴리오를 구성할 수 있음을 제시했다.
두 자산 간의 상관계수 $\rho$가 1보다 작을 때 투자기회집합선은 왼쪽으로 휘어지는데, 이것이 분산 투자의 효과다.
투자기회집합은 상관관계가 낮은 주식끼리 결합할수록 극대화된다.
포트폴리오(portfolio) 란?
- 두 개 이상 여러 자산의 조합
- 일반적으로 분산투자를 위해서 주식, 채권, 부동산과 같은 금융자산이나 실물자산 가운데 다수를 선택, 결합한 조합으로 통칭
- 재무(finance)에서는 주로 증권에 적용되어 투자위험을 줄이기 위한 분산투자 조합안의 의미로 사용
포트폴리오 이론
- Harry M. Markowitz 가 최초로 제공
- 확률과 분산을 이용해 포트폴리오 기대수익률과 위험을 수치화하는 기법 제시
- 포트폴리오 구성을 통한 분산투자로 투자위험의 감소화
최적 포트폴리오 선택
- 투자자의 기대효용을 극대화시키는 포트폴리오
- 평균-분산 모형(M-V model) 적용 가능
- 포트폴리오의 기대수익률과 분산 계산
포트폴리오 수익률의 기대수익률과 리스크를 계산하고 지배원리에 따라 포트폴리오를 걸러낸다.
그리고 무차별곡선을 이용해 최적 포트폴리오를 결정한다.
- 지배원리 : 선택의 대상이 되는 포트폴리오 범위(투자기회집합)의 축소
- 무차별곡선(indifference curve) : 최적 포트폴리오 결정 : 효율적 투자기회집합과 무차별곡선의 접점
두 개 주식으로 구성된 포트폴리오
평균(기대수익률)과 분산(리스크)
- 기대수익률 : 포트폴리오를 구성하는 개별자산의 확률분포와 예상수익률로부터 구한 평균값
- 위험 : 포트폴리오를 구성하는 개별자산의 예상수익률로부터 측정한 분산
포트폴리오의 기대수익률과 분산 구하기
- 포트폴리오 수익률의 기대값(평균)과 분산
$$
E(r_p) = \sum r_{ps} p_s
$$
$$
\sigma_p^2 = Var(r_p) = \sum [r_ps - E(r_p)]^2 p_s
$$ - 포트폴리오 구성하는 각 개별주식의 기대수익률을 가중평균과 가중한 분산과 공분산의 합계
$$
E(r_p) = \sum w_j E(r_j) = w_1 E(r_1) + w_2 E(r_2)
$$
$$
\sigma_p^2 = Var(r_p) = Var(w_1 r_1 + w_2 r_2) = w_1^2 + w_1^2 + w_2^2 + w_2^2 + 2w_1 w_2 \rho_{12} \sigma_1 \sigma_2
$$
개별 증권의 기대수익률과 분산, 증권간 공분산 또는 상관계수르 갖고 포트폴리오 기대수익률과 분산(리스크)을 구해보자.
| 국면 | 학률 | 주식A | 주식B |
| 호황 시 | 1/3 | 7% | 13% |
| 평상시 | 1/3 | 4% | 4% |
| 불황 시 | 1/3 | 1% | -5% |
주식 A와 B의 기대수익률은 사건(호황, 평상시, 불황)이 일어났을 때 결괏값, 즉, 수익률과 사건이 일어날 확률 1/3을 곱하고 총 합을 구한 것이다.
주식 A 기대수익률 = 1/3 x 7% + 1/3 x 4% + 1/3 x 1% = 4%
주식 B 기대수익률 = 1/3 x 13% + 1/3 x 4% + 1/3 x -5% = 4%
분산은 확률 x (각각의 결괏값 - 기댓값)$^2$ 을 전부 더한 것
주식 A 분산 = 1/3 x (7%-4%)$^2$ + 1/3 x (4%-4%)$^2$ + 1/3 x (1%-4%)$^2$ = 0.0006
주식 B 분산 = 1/3 x (13%-4%)$^2$ + 1/3 x (4%-4%)$^2$ + 1/3 x (-5%-4%)$^2$ = 0.0054
| 주식 A | 주식 B | |
| 기대수익률 | 4% | 4% |
| 분산 | 0.0006 | 0.0054 |
| 표준편차 | 0.0245 | 0.0734 |
포트폴리오의 기대수익률
투자자가 주식 A에 $w_A$ 만큼 투자해 $r_A$ 수익률을 얻고, 주식 B에 $w_B$만큼 투자해 $r_B$만큼 수익률을 얻을 것으로 예상한다면 이 포트폴리오의 기대수익률($r_p$)
$$
r_p = w_Ar_A + w_Br_B, w_1 + w_2 = 1
$$
투자 비중 합은 모두 합쳐서 1임.
만약 투자 비중을 각각 절반으로 한다면, 즉 50%씩 투자한다면
포트폴리오 기대수익률
= 주식 A 투자 비중 x 주식 A 기대수익률 + 주식 B 투자 비중 x 주식 B 기대수익률
= 50% x 4% + 50% x 4%
= 4%
포트폴리오 수익률 Python Code
import numpy as np
# 대괄호를 이용해 행렬을 만든다
# 국면별 확률
prob = np.matrix([[1/3, 1/3, 1/3]]) # 1x3 행렬
# 주식 A와 B의 수익률
stock_a = np.matrix([[7, 4, 1]])
sotck_b = np.matrix([[13, 4, -5]])
# 행렬 곱하기 연산
# 행렬의 차원을 맞추기 위해 matrix.T 함수를 사용해 전치시켜줌
# 개별 주식의 기대수익률
ex_a = prob * stock_a.T
ex_b = prob * stock_a.T
print('주식 A의 기대수익률은 %.2f%%' % ex_a)
print('주식 B의 기대수익률은 %.2f%%' % ex_b)
# %.2f 서식, %%는 % 기호
# 두 개 주식으로 구성된 포트폴리오의 기대수익률
weight = np.matrix([[0.5, 0.5]])
# '투자 비중 * 주식 기대수익률'
# ex_a와 ex_b는 1x1 행렬이므로 이를 값(스칼라)로 바꾼다.
# np.ndarray.item()
ex_ab = np.matrix([
# [ np.asscalar(ex_a) , np.asscalar(ex_b) ] >> deprecated
[ np.ndarray.item(ex_a) , np.ndarray.item(ex_b) ]
])
# 투자 비중 * 주식 기대수익률이라는 행렬 연산
# 둘 다 1x2 행렬이므로 ex_ab의 행렬을 전치 (ex_ab.T)해 행렬 곱을 계산
ex_p = weight * ex_ab.T
print('포트폴리오의 기대수익률은 %.2f%%' % ex_p)
# >> 주식 A의 기대수익률은 4.00%
# >> 주식 B의 기대수익률은 4.00%
# >> 포트폴리오의 기대수익률은 4.00%
행렬 연산으로 풀어보는 포트폴리오 기대수익률
import numpy as np
# 대괄호를 이용해 행렬을 만든다
# 국면별 확률
prob = np.matrix([[1/3, 1/3, 1/3]]) # 1x3 행렬
# 주식 A와 B의 수익률
stock_a = np.matrix([[7, 4, 1]])
sotck_b = np.matrix([[13, 4, -5]])
# 행렬 곱하기 연산
# 행렬의 차원을 맞추기 위해 matrix.T 함수를 사용해 전치시켜줌
# 개별 주식의 기대수익률
ex_a = prob * stock_a.T
ex_b = prob * stock_a.T
print('주식 A의 기대수익률은 %.2f%%' % ex_a)
print('주식 B의 기대수익률은 %.2f%%' % ex_b)
# %.2f 서식, %%는 % 기호
# 두 개 주식으로 구성된 포트폴리오의 기대수익률
weight = np.matrix([[0.5, 0.5]])
# '투자 비중 * 주식 기대수익률'
# ex_a와 ex_b는 1x1 행렬이므로 이를 값(스칼라)로 바꾼다.
# numpy.asscalar()
ex_ab = np.matrix([
# [ np.asscalar(ex_a) , np.asscalar(ex_b) ] >> duplicated
[ np.ndarray.item(ex_a) , np.ndarray.item(ex_b) ]
])
# 투자 비중 * 주식 기대수익률이라는 행렬 연산
# 둘 다 1x2 행렬이므로 ex_ab의 행렬을 전치 (ex_ab.T)해 행렬 곱을 계산
ex_p = weight * ex_ab.T
print('포트폴리오의 기대수익률은 %.2f%%' % ex_p)
# >> 주식 A의 기대수익률은 4.00%
# >> 주식 B의 기대수익률은 4.00%
# >> 포트폴리오의 기대수익률은 4.00%
참고로 책에 나와있던 np.asscalar() 는 1차원 행렬을 스칼라로 변환해주는 함수인데 deprecated 되었다.
대신 np.ndarray.item() 사용가능!
포트폴리오의 위험
$$
\sigma_p^2 = Var(r_p) = Var(w_1 r_1 + w_2 r_2)
$$
$$
= w_1^2 + w_1^2 + w_2^2 + w_2^2 + 2w_1 w_2 \sigma_{12}
$$
$$
= w_1^2 + w_1^2 + w_2^2 + w_2^2 + 2w_1 w_2 \rho_{12} \sigma_1 \sigma_2
$$
이때 $\sigma_{12}$ 는 공분산인데,
$$
\rho_{12} = \frac{\sigma_{12}}{\sigma_1 \sigma_2}
$$
임을 이용해서 상관계수 $\rho$를 구할 수 있다.
포트폴리오 위험 =
주식 A 투자 비중$^2%$ x 주식 A 분산 + 주식 B 투자 비중$^2%$ x 주식 B 분산
+ 2 x 주식 A 투자 비중 x 주식 B 투자 비중 x 포트폴리오 공분산
포트폴리오 공분산 =
호황 시 확률 × (주식 A 수익률 - 주식 A 기대수익률) × (주식 B 수익률 - 주식 B 기대수익률)
+ 평상시 확률 × (주식 A 수익률 - 주식 A 기대수익률) × (주식 B 수익률 - 주식 B 기대수익률)
+ 불황 시 확률 × (주식 A 수익률 - 주식 A 기대수익률) × (주식 B 수익률 - 주식 B 기대수익률)
= 1/3×(7% - 4%)(13% - 4%) + 1/3×(4% - 4%)(4% - 4%) + 1/3×(1% - 4%)(-5% - 4%)
= 0.09% + 0% + 0.09% = 0.18%
으로 나타낸다.
이 공분산을 이용해 포트폴리오 분산(위험)을 구하면
= 50%2 × 0.06% + 50%2 × 0.54% + 2 × 50% × 50% × 0.18%
= 0.00015 + 0.00135 + 0.0009 = 0.0024
포트폴리오 표준편차는 = $\sqrt{0.0024}$ =0.049 이다.
| 주식A | 주식B | 포트폴리오 P | |
| 기대수익률 | 4% | 4% | 4% |
| 분산 | 0.0006 | 0.0054 | 0.24%^2 |
| 표준편차 | 0.0245 | 0.0734 | 0.0490 |
마지막으로 상관계수 까지 구해보자.
$$
\rho_{12} = \frac{\sigma_{12}}{\sigma_1 \sigma_2}
$$
= 0.18% / (2.45% x 7.35%) = 1.0
포트폴리오 분산 python code
import math # sqrt 함수 사용하기 위해 math 모듈 호출
# 경기 국면별 확률과 주식 기대수익률
stock_a = [0.07, 0.04, 0.01]
stock_b = [0.13, 0.04, -0.05]
prob= [1/3, 1/3, 1/3]
# 주식 a와 b의 경기 국면에 따른 수익률 기댓값을 저장할 변수 준비
ex_a = 0
ex_b = 0
# 주식 a와 b의 기댓값
ex_a = sum(s*p for s, p in zip(stock_a, prob))
ex_b = sum(s*p for s, p in zip(stock_b, prob))
# 분산을 저장할 변수와 투자 비중
var_a = 0
var_b = 0
wgt_a = 0.5
wgt_b = 0.5
# 리스트 stock_a, prob에서 각각 데이터를 변수 s와 p로 받아 반복
# 확률 x 편차 제곱
var_a = sum(p*(s-ex_a)**2 for s,p in zip(stock_a, prob))
var_b = sum(p*(s-ex_b)**2 for s,p in zip(stock_b, prob))
print('주식 A의 분산은 {:.2f}'.format(var_a))
print('주식 B의 분산은 {:.2f}'.format(var_b))
# 포트폴리오 분산
# 공분산, 분산, 표준편차 필요
cov = sum(p * (a-ex_a) * (b-ex_b) for a, b, p in zip(stock_a, stock_b, prob))
var_p = wgt_a**2 * var_a + wgt_b**2 * var_b + 2 * wgt_a * wgt_b * cov
std_p = math.sqrt(var_p)
print('포트폴리오 분산은 {:.2f}'.format(var_p))
print('포트폴리오 표준편차은 {:.2f}'.format(std_p))
# >> 주식 A의 분산은 0.06%
# >> 주식 B의 분산은 0.54%
# >> 포트폴리오 분산은 0.24%
# >> 포트폴리오 표준편차은 4.90%
행렬 연산으로 풀어보는 포트폴리오 분산
$$
\begin{bmatrix}w_1 w_1 \sigma_{11} & w_1 w_2 \sigma_{12} \ w_1 w_2 \sigma_{12} & w_2 w_2 \sigma_{22} \end{bmatrix}
$$
n개 주식으로 만든 포트폴리오
- 포트폴리오 수익률
$$
r_p = w_1r_1 + w_2r_2 + ... + w_nr_n = \sum w_ir_i
$$
$$
w_1 + w_2 + ... + w_n = \sum w_i = 1
$$ - 포트폴리오 기대수익률 : E[r_p]
$$
E(r_p) = w_1 E(r_1) + w_2 E(r_2) + ... + w_n E(r_n) = \sum w_i E(r_i)
$$
n개 포트폴리오 수익률 python code
import numpy as np
# 자산 개수
numStocks = 3
# 세 가지 경기 국면별로 자산의 개수만큼 주식의 수익률을 난수로 생성
returns = np.random.randn(3, numStocks) # [3xnumStocks] 배열
print('1. 난수로 만드는 국면별 주식의 수익률: \n', returns)
# 세 가지 경기 국면별 확률.
# 난수로 만드는 대신 전체 합이 1이 되어야 함
prob = np.random.rand(3) # 난수 3개
prob = prob / prob.sum() # 생성한 난수를 난수 합계로 나눠 합이 1
print('2. 경기 국면별 각 확률: \n', prob)
# 경기 국면별 확률과 수익률을 행렬 곱셈
expectedReturns = np.matmul(prob.T, returns)
# prob.T는 prob 전치행렬.
# matmul() = 행렬 곱
expectedReturns = prob.T * returns
print('3. 각 주식의 기대수익률: \n', expectedReturns)
# 투자 비중
# 주식 개수(numStocks)만큼 난수를 만든 후 난수 합으로 나눠 전체 투자 비중의 합을 1이 되도록
weights = np.random.rand(numStocks)
weights = weights/weights.sum()
print('4. 투자 비중*기대수익률: \n', weights)
# 포트폴리오 기대수익률
# 각각 투자 비중 x 주식 기대수익률의 곱을 모두 합한 값
expectedReturnOfPortfolio = np.sum(weights*expectedReturns)
print('5. 포트폴리오 기대수익률: {:.2%}'.format(expectedReturnOfPortfolio))
# 1. 난수로 만드는 국면별 주식의 수익률:
# [[-1.00423803 0.03795484 1.31418638]
# [ 1.01286473 -1.66110769 1.89096977]
# [-0.34904275 -0.72550796 -0.30826369]]
# 2. 경기 국면별 각 확률:
# [0.11299366 0.27527811 0.61172823]
# 3. 각 주식의 기대수익률:
# [[-0.11347253 0.01044814 0.80392491]
# [ 0.11444729 -0.45726658 1.1567596 ]
# [-0.03943962 -0.19971646 -0.1885736 ]]
# 4. 투자 비중*기대수익률:
# [0.27119828 0.20525735 0.52354437]
# 5. 포트폴리오 기대수익률: 78.46%
실제 데이터로 포트폴리오 기대수익률 계산하기
2022.11.25 - [TIL/09_QUANT] - [금융Python] 기대수익률 분석 / CAPM (2)
(위 포스팅 내용과 조금 중복됨.
아래 내용은 기대수익률과 분산 구하는 데에 조금 더 집중 되어 있고, 위의 내용은 CAPM까지 구한 내용!)
실제 데이터를 사용하므로 경기 국면별 확률에 따른 기대수익률이 아닌 실제 수익률 사용
수정주가
수장주가는 액명변경, 유무상증자 등과 같은 이벤트를 주가에 반영해 현재 주가의 수준을 과거와 비교할 수 있또록 과거 주가도 함께 수정하는 것을 말한다. 정확하게 분석하려면 종가 대신 수정주가를 사용해야 한다.
import numpy as np
import pandas as pd
from pandas_datareader import data as web
import random
# 몇 가지 종목 코드(ticker)를 가지고 포트폴리오에 포함된 주식 리스트
tickers = ['MMM', 'ADBE', 'AMD', 'GOOGL', 'GOOG', 'AMZN']
# 3M, 어도비, Advanced Micro Devices, 구글 A, 구글 C, 아마존
# 수정주가를 담을 빈 데이터프레임
adjClose = pd.DataFrame()
# for문을 이용해 trickers 리스트를 반복하면서 종목 코드를 꺼내고
# dataReader 함수를 이용해 수정주가 데이터를 내려받는다.
# 데이터는 야후 파이낸스를 통해 얻음
for item in tickers:
adjClose[item] = web.DataReader(item, data_source='yahoo', start='01-01-2020')['Adj Close']
adjClose
# pandas의 pct_change 함수를 사용해 데이터 변화량을 %로 계산
# dailySimpleReturns 일간 수정주가 데이터를 일간수익률로 변환
dailySimpleReturns = adjClose.pct_change()
print('dailySimpleReturns(일간수익률)의 데이터형: ', type(dailySimpleReturns))
# >> dailySimpleReturns(일간수익률)의 데이터형: <class 'pandas.core.frame.DataFrame'>
capm 기대수익률 분석 포스팅에서 했던 내용
일일수익률 벡터
(매도가격-매수가격)/매수가격 = 판다스의 pct_change() 메서드
- NaN : 과거 데이터가 없기 떄문에 NaN값이 나옴
# 기대수익률 대신 일간 수익률의 평균 계산
meanReturns = np.matrix(dailySimpleReturns.mean())
# 일간 수익률을 연간수익률로 환산하려고 할때
# 연간수익률 = 영업일을 1년 365일 중 252일이라고 했을 때, 일간수익률에 252를 곱하면 됨
annualReturns = dailySimpleReturns.mean() * 252
meanReturns
# >> matrix([[-0.0001408 , 0.00033672, 0.00125942, 0.0007156 , 0.00071926,
# 0.00030427]])
# 주식의 개수만큼 투자 비중을 만든다.
numAssets = len(tickers)
# 투자 비중은 난수로 만들고 투자 비중을 비중의 합으로 나눠 투자 비중의 합이 1이 되도록
weights = np.random.randn(numAssets)
weights = weights / sum(weights)
# 투자 비중과 연간 환산수익률을 곱해 포트폴리오 기대수익률 계산
# weights와 meanReturns의 차원은 1x6
# 곱셈 연산을 위해 meanReturns를 전치
portRtnExp = np.sum(weights * meanReturns.T)
portRtnExp
# >> 0.002271066123381185
분산 계산
# 공분산을 계산해주는 함수 cov()
print('dailySimpleReturns.cov() 결과의 데이터형: ', type(dailySimpleReturns.cov()))
# >> dailySimpleReturns.cov() 결과의 데이터형: <class 'pandas.core.frame.DataFrame'>
# 공분산
pcov = dailySimpleReturns.cov().values
# 행렬연산으로 분산 계산.
# [비중 * 공분산 행렬 * 비중의 전치행렬]
varp = weights * pcov * weights.T
print('포트폴리오 분산: ', varp)포트폴리오 분산: [[6.14753445e-04 6.96514091e-05 5.23595522e-05 7.94748922e-04
9.33959035e-04 1.20838878e-04]
[3.09324769e-04 2.87236405e-04 1.46416628e-04 1.94724371e-03
2.25497724e-03 4.33959191e-04]
[3.88819055e-04 2.44825825e-04 3.07559558e-04 2.22901387e-03
2.55314570e-03 5.23121951e-04]
[3.12360296e-04 1.72330201e-04 1.17974197e-04 2.21222186e-03
2.55280636e-03 3.63836816e-04]
[3.14734825e-04 1.71109587e-04 1.15861982e-04 2.18881455e-03
2.55484855e-03 3.64146683e-04]
[2.21307664e-04 1.78959134e-04 1.29015264e-04 1.69539358e-03
1.97901532e-03 6.11213503e-04]]
참고 자료