
그럼 기대수익률 분석 / CAPM (1)에 이어서 실제 Python을 통해 실전 분석을 해보자.
먼저, !pip install finance-datareader로 다운로드 해주고, 라이브러리 불러오기
import numpy as np
import pandas as pd
import FinanceDataReader as fdr
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import scipy as sp위 강의에서 사용한 종목은 다음과 같다.
- Market : KOSPI200 (KS200)
- Indicidual Asset : 삼성전자 (005930), 오뚜기(007310), SK하이닉스(000660)
- 삼성전자는 마켓을 잘 따라갈 것 같아서. kospi에서 시총이 20-30% 정도 차지
- 오뚜기는 필수 소비자이기 때문에
- sk하이닉스는 삼성전자와 얼마나 다를까
- 무위험자산(현금성자산) : cd금리, 단기국채 등.. KODEX 단기채권(153130), KOSEF 단기자금(130730)
- 코세프 단기자금 : 현금성자산(MMF)
그런데 내가 했을 때는 KS200이 안불러와졌다.ㅠㅠ
HTTP Error 404: Not Found - symbol "KS200"not found or invalid periods
나는 왜 오늘 꺼만 나오는지 모를 따름..
그래서 일단 나는 KS11로 진행했다. (내 맘대로 바꿔도 되는지는 모르겠지만 일단 진행)
- KS11 : KOSPI 지수
tmp_df = fdr.DataReader("KS11", start='2019-01-01', end='2019-12-31')
tmp_df.head()
# Adj_Close : Close
이런 주식 데이터가 나온다.
- Open : 해당 개장일 시가
- High : 해당 개장일 고가
- Low : 해당 개장일 저가
- Adj Close : 해당 개장일 종가
- Volume : 해당 개장일의 거래량
market = fdr.DataReader("KS11", start="2019-1-1", end="2019-12-31")[['Adj Close']]
market = market.rename(columns={'Adj Close': 'Close'})
se = fdr.DataReader("005930", start="2019-1-1", end="2019-12-31")[['Close']] # 삼성
otg = fdr.DataReader("007310", start="2019-1-1", end="2019-12-31")[['Close']] # 오뚜기
skh = fdr.DataReader("000660", start="2019-1-1", end="2019-12-31")[['Close']] # sk하이닉스
cash = fdr.DataReader("130730", start="2019-1-1", end="2019-12-31")[['Close']] # 현금성자산(KOSEF 단기자금)fdr.DataReader를 통해 해당 주식 심볼을 불러오고 시작 날짜와 종료 날짜를 지정한다음, 각 날짜의 종가를 가져온다.
일일 수익률
일일 수익률 = (매도 가격 - 매수가격) / 매수가격
pct_change()를 통해 일일 수익률을 바로 구할 수 있다.
## 일일수익률 벡터
### (매도가격-매수가격)/매수가격 = 판다스의 pct_change() 메서드
market.pct_change()
# NaN : 과거 데이터가 없기 떄문에 NaN값이 나옴
- log return을 통해 식을 구하는 방법
def log_return(series):
return np.log(series/series.shift(1)).fillna(0)market_rtn = np.log(market / market.shift(1)).fillna(0)
market_rtn.columns = ['market']
se_rtn = np.log(se / se.shift(1)).fillna(0)
se_rtn.columns = ['se']
otg_rtn = log_return(otg)
otg_rtn.columns = ['otg']
skh_rtn = log_return(skh)
skh_rtn.columns = ['skh']
cash_rtn = log_return(cash)
cash_rtn.columns = ['cash']
# 로그를 치하는 이유 : 컴퓨테이션이 굉장이 편리해서. log로 인해 summation 연산이 가능
# computer 입장에서 곱하기 연산보다 더하기 연산이 편함
두 가지의 방법의 결과는 똑같다.
위 결과들을 한번에 관리하기 위해 리스트로 담는다.
(concat으로 하면 더 편할 듯??)
rtns = [market_rtn, se_rtn, otg_rtn, skh_rtn, cash_rtn]
rtns이 분은 데이터프레임을 리스트로 담았는데, 이런 방법은 처음 봤다. concat으로 하면 편할 것 같은데.. 내 기준으로 조금 비효율적인 것 같긴하지만 일단 진행
정규성 검정
seaborn의 distplot을 통해 그래프로 간단히 시각화할 수 있다.
import warnings
warnings.simplefilter('ignore')
plt.figure(figsize=(10,10))
for i in range(4):
plt.subplot(2,2,i+1)
sns.distplot(rtns[i], color='red', fit=sp.stats.norm)
plt.title(rtns[i].columns)
plt.show()
- 검은색 라인이 정규분포
- 정규분포에 딱 맞지 않음
- tail쪽 부분이 정규분포보다 튀어나와있음 => 정확하게 fit되진 않지만 정규분포 가정은 가능
누적 수익률
# 수익률을 누적했을 때
# 누적 수익률
plt.figure(figsize=(12,6))
for rtn in rtns:
plt.plot(np.exp(rtn.cumsum()), label=rtn.columns[0])
plt.xticks(rotation=45)
plt.legend()
plt.show()
# cumsum : 누적합, log를 사용하기 때문에 누적 곱하기 효과
- cash는 연수익률 약 2%, 이자율정도만 얻는 정도
- 오뚜기는 우하향..
시장 초과수익률
시장 초과 수익률 = market 일일 수익률 - 현금성자산(무위험자산) 수익률
각 종목들의 초과 수익률을 계산
# 그냥 수익률
rtn_df = pd.concat(rtns, axis=1)
excess_market = rtn_df.market - rtn_df.cash
# market의 일일 수익률 - 현금성자산(무위험자산) 수익률 = 시장 초과수익률 series를 구함
excess_se = rtn_df.se - rtn_df.cash
excess_otg = rtn_df.otg - rtn_df.cash
excess_skh = rtn_df.skh - rtn_df.cash
excess_rtn_df = pd.concat([cash_rtn, excess_market, excess_se, excess_otg, excess_skh], axis=1)
excess_rtn_df.columns = ['cash','market','se','otg','skh']
excess_rtn_df.head()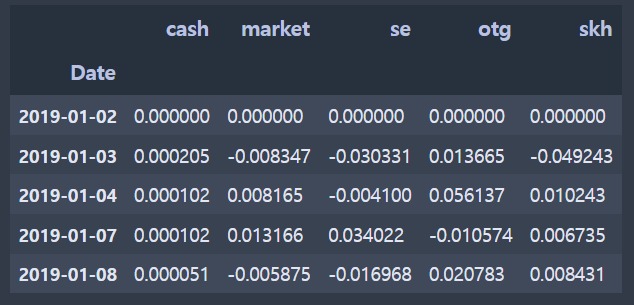
결국 concat 쓰시더랔ㅋㅋㅋㅋ 역시 판다스 짱..
- 방금 구한 결과들을 시각화
excess_rtn_df.plot(figsize=(12,6))
- sk하이닉스는 튀는 정도 (변동성) 이 굉장히 심함 => 그만큼 risky한 자산이었다 (2019년 기준)
- 누적 수익률을 봤을 때 우상향하고 있지만, 변동성도 심헀다.
- high risk, high return 이었다.
내가 금융 도메인에 지식이 더있었다면 더 많은 인사이트들을 발견했을 것 같은데 매우 아쉽다. 더 호기심이 불러일으켜 지는 그래프다.
linear regression
전에 배운 개념이었던 포트폴리오 초과 수익률의 식을 다시 확인해보자.
$$
r_P = \alpha_P + \beta_P r_M + \epsilon_P
$$
- $r_p$ : 포트폴리오 초과 수익률
- $r_M$ : 시장 초과 수익률
위 단계에서 우리는 시장 초과 수익률 $r_M$ 을 excess_market 으로 구했다.
이를 이용해 회귀식을 만들어 보자.
# import statsmodels.api as sm
X = sm.add_constant(excess_market) # 독립변수에 절편 추가
X.columns = ['constant','market']
model_se = sm.OLS(excess_se, X)
result_se = model_se.fit()
print(result_se.summary())
X에 해당하는 독립변수 만들기 위하여 statsmodels의 상수항 결합을 위함 add_constant 함수를 이용한다.
이는 절편항이 포함된 선형 회귀 모형을 만드는 과정인데 1로 이루어진 cont 칼럼이 만들어진다.
constant와 market을 변수로 한 회귀 식을 OLS를 통해 만들 수 있다. -> fit()을 통해 ResultWrapper를 만들고 -> summary()를 통해 결과 레포트를 전달 받는다.
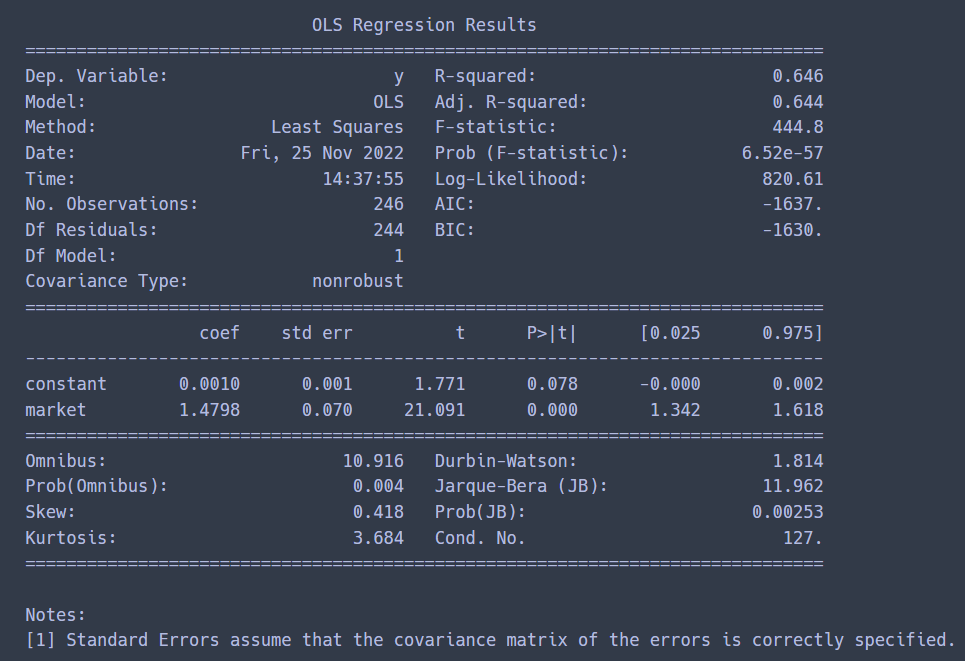
삼성전자
- R-squared : 성능 지표. 잘 fit 한 정도. 모델이 얼마나 잘 적합되었는지
- 0.646 백분율로 64%정도 설명할 수 있다.
- constant : 0.0010, pvalue = 0.078
- pvalue를 0.05를 기준으로 하는데, 0.05보다 크므로 통계적으로 유의하지 않음 => const값을 무시할 수 있다.
- market 0.000 => 통계적으로 유의하고, beta값으로 가능. 즉, beta 값 = 1.4798
- beta : 시장 위험에 대한 개별 자산의 위험 (=시장에 얼마나 민감하게 반응하는지 판단)
= 시장이 1만큼 움직일 때 삼성전자가 1이상으로 움직일 가능성이 있다. - market에 예민하게 반응한다.
X = sm.add_constant(excess_market)
X.columns = ['constant','market']
model_otg = sm.OLS(excess_otg, X)
result_otg = model_otg.fit()
print(result_otg.summary())
오뚜기
- Rsquae = 0.061은 거의 설명을 못하고 있음
- market의 coef도 1보다 낮음 -> market에 둔감하다
- pvalue도 0.00으로 통계적으로 유의미하기 때문에 beta를 0.3531라고 할 수 있다.
- 오뚜기의 기대수익률을 설명하는데 있어서, market factor가 적합하느냐 No.
X = sm.add_constant(excess_market)
X.columns = ['constant','market']
model_skh = sm.OLS(excess_skh, X)
result_skh = model_skh.fit()
print(result_skh.summary())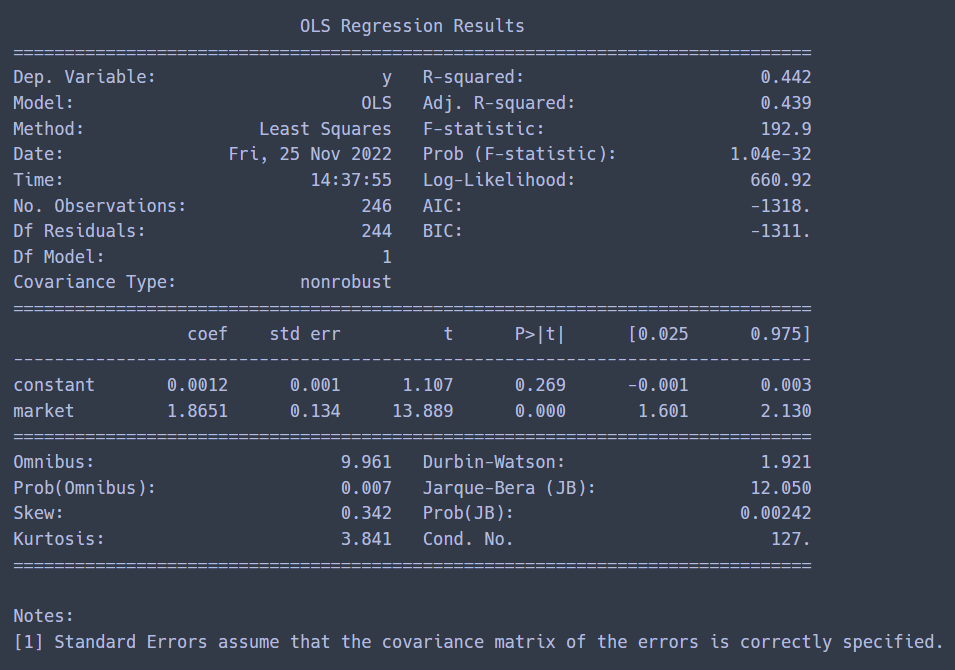
sk하이닉스
- Rsquare 0.442로 삼성전자와 비교해보면 설명력이 떨어진다고 할 수 있다.
- market의 pvalue는 0.00으로 통계적으로 유의함으로 beta = 1.86
- 시장에 굉장히 민감. 시장의 risk에 처해있는 정도가 꽤 높다는 것을 의미.
capm의 이론상 contant 가 거의 0에 수렴 => 알파를 기대할 수 없다.
즉, 포트폴리오 초과 수익률의 식에서 알파를 잔차와 합치던 과정이 여기서 나온 것이었다.
$$
r_P = \alpha_P + \beta_P r_M + \epsilon_P
$$
$$
r_P = \beta_P r_M + \epsilon_P
$$
- market term과 residual term으로 구분할 수 있다.
- alpha는 무시할 수 있다.
우리가 궁극적으로 찾고자 하는 베타는 다음으로 구할 수 있다.
result_se.params['market'] # = betase_market_hat = excess_market * result_se.params['market']
se_resid_hat = excess_se - se_market_hat
otg_market_hat = excess_market * result_otg.params['market']
otg_resid_hat = excess_otg - otg_market_hat
skh_market_hat = excess_market * result_skh.params['market']
skh_resid_hat = excess_skh - skh_market_hat
# se_market : r_M
# result_se.params : summary의 params
market 추정량은 초과 수익률에 대해 beta를 곱한 값으로 나타낼 수 있다.
잔차 추정량은 포트폴리오 초과 수익률에 대해 시장 기대 수익률 추정값을 뺀 값
($r_p - \beta r_M$)
CAPM
이제, CAPM을 구해보자.
$$
E[R_p] = R_f + \beta(E[R_M] - R_f)
$$
expected_market = excess_market.mean() * 252 # 시장 초과 기대수익률을 연율화 (E[R_M]-R_f)
betas = np.array([0, 1, result_se.params['market'],
result_otg.params['market'], result_skh.params['market']])
# ['무위험자산','시장','삼성전자','오뚜기','sk하이닉스']에 해당하는 베타 상수
# 0 : 무위험자산(KOSEF 단기 자금), 1 : 자기 자신에 대한 covariance
# np.array를 통해 벡터 연산이 가능
expected_rf = cash_rtn.mean().cash * 252
expected_rtn = expected_rf + betas * expected_market # expected returnexpected_market: excess_market.mean() * 252 = 시장의 연율화된 기대 초과 수익률 이다.expected_rf: $R_f$expected_rtn: $E[R_p]$
이렇게 계산 식을 이용하여 각 변수를 구한 후, expected_rtn이라는 최종 결과가 나왔다.
이제 구한 결과를 시각화해보자.
# matplotlib 한글 폰트 오류 문제 해결
from matplotlib import font_manager, rc
font_path = "C:\Windows\\Fonts\\malgun.ttf" #폰트파일의 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)labels = ['무위험자산','시장','삼성전자','오뚜기','sk하이닉스']
plt.figure(figsize=(12,6))
plt.plot(betas, expected_rtn)
plt.scatter(betas, expected_rtn, marker='o', c='red')
for i, text in enumerate(expected_rtn): # for문을 돌면서 그 앞에 index 값까지 return 해줌
plt.annotate(labels[i], (betas[i], expected_rtn[i]+0.004)) # 라벨명, 위치 주석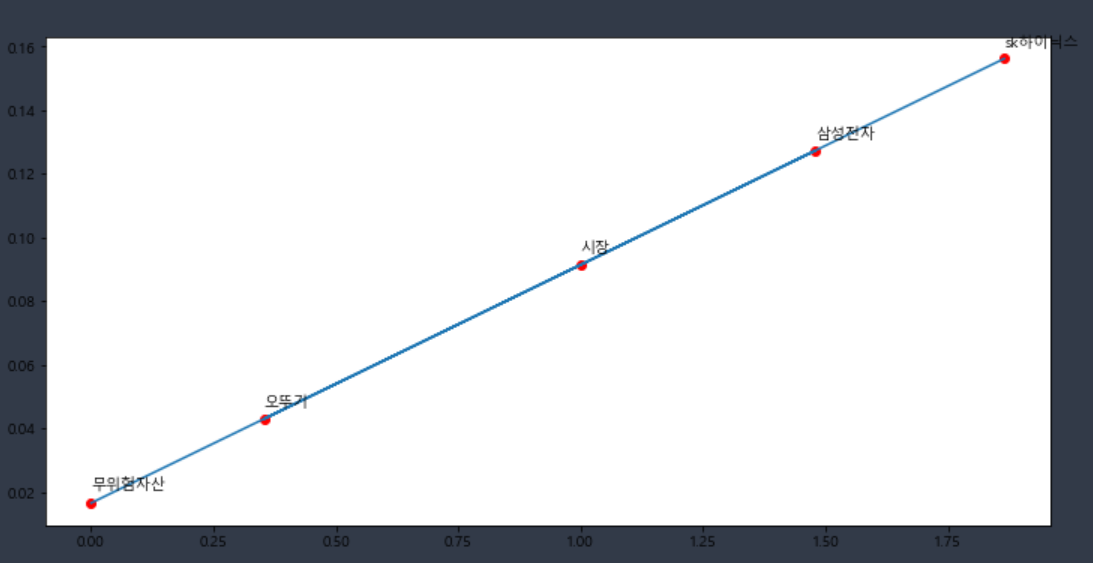
- beta가 클수록 return도 큼
- 시장 자체가 상승 곡류(양의 수익률)을 내고 있었기 때문에 우상향 그래프가 나온 것임
- 지금은 종목이 몇 개 안되고, 1년만 살펴봤기 때문에 이렇게 간단한 그래프가 나왔지만, 더 많은 기간, 더많은 종목을 살펴봤을 때 양의 수익률뿐만 아니라 음의 수익률도 있을 테고 그렇다면 더 복잡한 그래프가 나올 것이다.
마지막으로, 총 Risk (포트폴리오의 초과 수익률의 분산)을 계산해보면
$$
Var(r_P) = \sigma^2_P = \beta^2_P \sigma^2_M + Var(\epsilon_P)
$$
market_risk = excess_market.std()
stock_risk = excess_rtn_df[['se','otg','skh']].std().values
resid_risk = np.sqrt(stock_risk ** 2 - (betas[2:] * market_risk)**2)
risk_result = pd.DataFrame({'beta':betas[2:],
'total risk':stock_risk,
'resid rsik':resid_risk},
index=['se','otg','skh'])
risk_resultmarket_risk: $\sigma_M$ (market 초과 수익률 표준편차)stock_risk: $\sigma_p$ (포트폴리오 초과수익률 표준편차)resid_risk: $\sqrt{\sigma_p^2 - \beta_p^2 \sigma_M^2}$ ($\episilon_P$)

Beta Hedging
- 헷징 : 회피한다는 의미 (beta를 회피)
- 시장의 리스크에 대한 beta를 헷징(회피)
- => market의 impact가 내가 가진 개별 자산의 risk에 영향을 주지 않게 됨
- beta만큼 scale을 해서 자체적으로 가지고 있는 market의 상품을 숏(매도)하면 됨
model_bh = sm.OLS(excess_se - excess_market * result_se.params['market'], sm.add_constant(excess_market))
# 삼성전자 daily 초과 수익률 - 시장초과수익률 * 베타 = 매도?
result_bh = model_bh.fit()
result_bh.summary()- 결과적으로 market term이 coef가 0에 가깝고 pvalue도 1임
- => 더이상 market의 impact가 영향을 주고 있지 않고 있음
- hedging하고 싶은 자산에 대해서 hedging하고 싶은 risk를 선형으로 빼주면 됨. 매도하는 양은 beta만큼 곱해서 숏을 쳐준 상태인 수익률 series
(완전한 이해는 못함..)
참고 자료
https://m.blog.naver.com/j9fbm93/221978017413
CAPM (자본자산 가격결정모형)이거에 대해 공부해보자!
이웃님들 반가워요~~ 즐거운 월요일 보내고 계신가요~? 오늘 날씨가 정말 정말 좋은데요 그래서 오늘도 아...
blog.naver.com
https://www.youtube.com/watch?v=rgW7hTyGuxs&list=PL7SDcmtbDTTyFvuI_rIwaXyxggTNAyqWC&index=2