
서울시 구별 CCTV 현황 분석하기
- 서울시 각 구별 CCTV수를 파악하고, 인구대비 CCTV 비율을 파악해서 순위 비교
- 인구대비 CCTV의 평균치를 확인하고 그로부터 CCTV가 과하게 부족한 구를 확인
- CCTV 현황 파악하기
import pandas as pd
import numpy as np
CCTV = pd.read_csv('CCTV_in_Seoul.csv', encoding='CP949',header=None)
CCTV.head()
>> csv 파일을 불러오기
>> 0행인 ※ 부분이 header로 나와서 header=None 지정해줌
CCTV = CCTV.drop(0)
CCTV.rename(columns=CCTV.iloc[0],inplace=True)
CCTV_Seoul = CCTV.drop([1,2])
CCTV_Seoul.reset_index(drop=True,inplace=True)>> 0행이었던 ※ 내용을 삭제해주고
>> rename()을 통해 열을 다시 지정해줌
>> 필요없는 데이터를 버리고 index를 초기화해줌
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0] : '구별'}, inplace=True)
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[1] : '소계'}, inplace=True)
>> column명 변경
>> info()를 찍어보면 결측값이 존재하는 것을 볼 수 있다.
>> 이 결측값을 그 해에 설치된 CCTV가 없는 것으로 보고 0으로 처리해줌
CCTV_Seoul = CCTV_Seoul.fillna(0)
# 소계 : ',' 제거
s1 = CCTV_Seoul.iloc[:,1].replace(',','')
CCTV_Seoul.iloc[:,1] = s1.map(lambda x : x.replace(',',''))
# object >> int
for i in CCTV_Seoul.columns[1:]:
CCTV_Seoul[i] = CCTV_Seoul[i].astype('int')>> ',' 제거
>> 결측값이 사라지고 object가 int로 변경
# 2012년 이전 ~ 2016년 까지를 '2016년 이전'에 다 넣어줌
CCTV_Seoul['2016년 이전'] = CCTV_Seoul.iloc[:,2:8].sum(axis=1)
CCTV_Seoul['2016년 이전']
# 2016년 이전 : 기준(분모), 5개년도
CCTV_Seoul['최근증가율'] = (CCTV_Seoul['2017년'] + CCTV_Seoul['2018년'] + \
CCTV_Seoul['2019년'] + CCTV_Seoul['2020년'] +\
CCTV_Seoul['2021년']) / CCTV_Seoul['2016년 이전'] * 100
CCTV_Seoul.sort_values(by='최근증가율', ascending=False).head(5)
CCTV_Seoul = CCTV_Seoul.drop(CCTV_Seoul.columns[2:8],axis=1)
CCTV_Seoul = CCTV_Seoul[['구별','소계','2016년 이전','2017년','2018년','2019년','2020년','2021년','최근증가율']]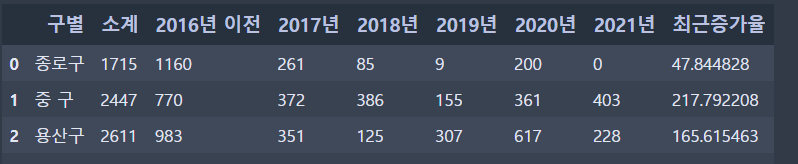
>> 최근 5년간 CCTV 개수의 증가율을 보기 위함
>> 먼저 2016년 이전까지의 개수를 구해주고
>> (5개년도 CCTV 개수 합) / (2016년 이전 CCTV 개수) *100 = 최근 5년간 증가율
- 서울시 인구 데이터 파악하기
pop_Seoul = pd.read_csv('population_Seoul.csv', encoding='CP949',
header = 2,
usecols = [1,3,6,9,13])
pop_Seoul.rename(columns={pop_Seoul.columns[0] : '구별',
pop_Seoul.columns[1] : '인구수',
pop_Seoul.columns[2] : '한국인',
pop_Seoul.columns[3] : '외국인',
pop_Seoul.columns[4] : '고령자'}, inplace=True)
pop_Seoul.drop([0], inplace=True)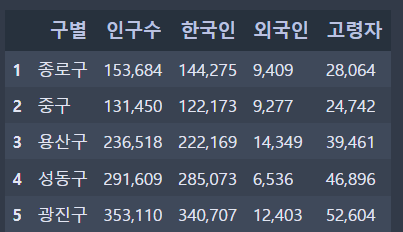
>> 2022년도 1/4분기의 인구수
# ',' 제거
for i in pop_Seoul.columns[1:]:
s2 = pop_Seoul[i]
pop_Seoul[i] = s2.map(lambda x : x.replace(',',''))
# 1~4열 : object >> int
for i in pop_Seoul.columns[1:]:
pop_Seoul[i] = pop_Seoul[i].astype('int')>> 마찬가지로 ','를 제거해주고 int로 변경
pop_Seoul['한국인비율'] = pop_Seoul['한국인']/pop_Seoul['인구수']*100
pop_Seoul['외국인비율'] = pop_Seoul['외국인']/pop_Seoul['인구수']*100
pop_Seoul['고령자비율'] = pop_Seoul['고령자']/pop_Seoul['인구수']*100
pop_Seoul.head()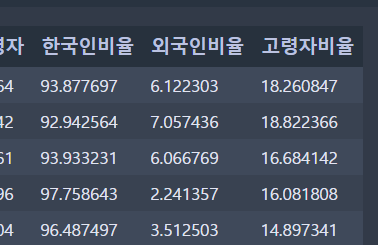
>> 각 구별 인구수 대비 한국인, 외국인, 고령자의 비율을 구함
- CCTV 개수는 증가하는데 어떤 기준으로 증가하고 있을까?
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on='구별')
data_result = data_result.drop(data_result.columns[2:8],axis=1)
data_result.set_index('구별', inplace=True)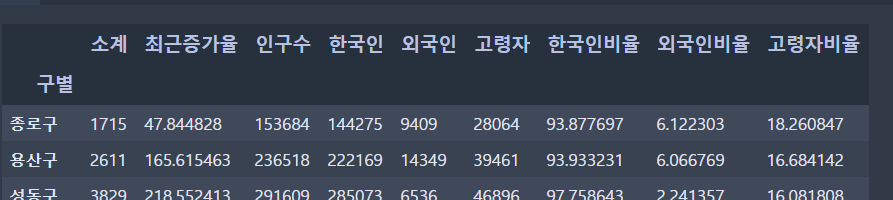
>> CCTV 현황과 서울의 구별 인구 데이터를 '구'를 기준으로 데이터프레임을 합침
- 상관계수 분석
np.corrcoef(data_result['인구수'],data_result['소계'])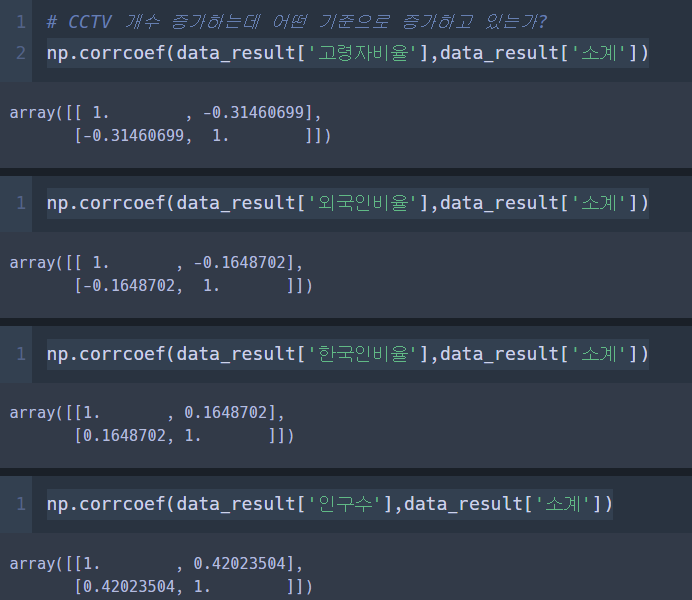
scipy.stats.pearsonr(data_result['인구수'],data_result['소계'])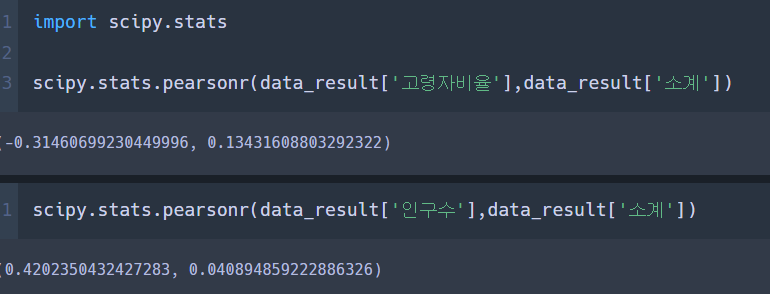
# 상관계수는 -1~1의 값을 가진다. 1과 -1에 가까워 질수록 상관관계가 크다.
# '고령자비율','외국인비율','한국인비율','인구수' 각각을 전체 CCTV 개수와의 상관관계를 비교
# 음(-)의 상관관계를 가지는 고령자비율과 외국인비율을 비교했을 때는 고령자비율이,
# 양(+)의 상관관계를 가지는 한국인비율과 인구수를 비교했을 때는 인구수가 더 높은 상관관계가 있는 것으로 나타남
# 인구수는 0.42정도로 약한 상관이 있고 (0.4<=r<0.6), p값은 0.04로 통계적으로 유의미한 값 (p<0.05)
# 고령자비율은 -0.31으로 상관이 거의 없음 (r<=0.4), p값은 0.1이 넘으므로 유의미하지 않음
- 상관관계에 따른 산점도를 그려보자
# 그래프를 노트북 안에 그리기 위해 설정
%matplotlib inline
# 필요한 패키지와 라이브러리 불러오기
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
# 폰트 지정하기
plt.rcParams['font.family'] = 'gulim'plt.figure()
data_result['소계'].sort_values().plot(kind='barh',grid=True,figsize=(8,8))
plt.show()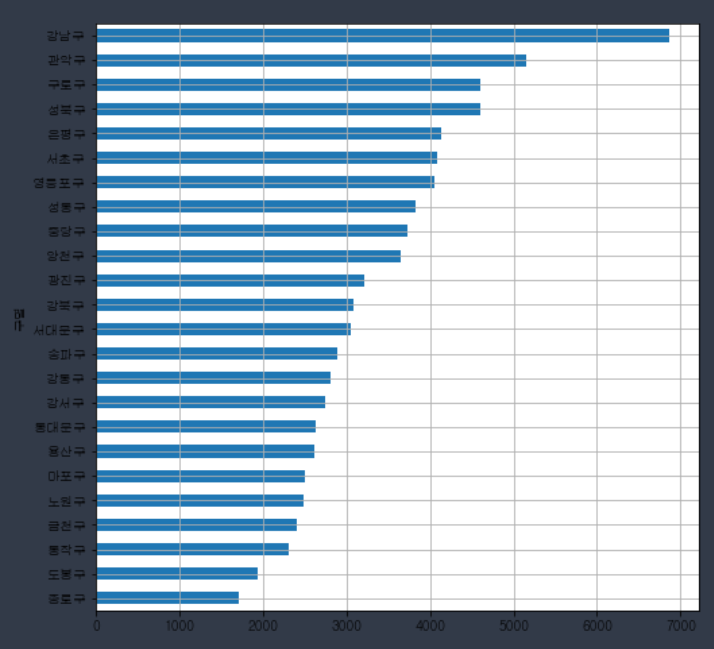
>> '구'를 기준으로 CCTV 개수를 보면 강남구 > 관악구 > 구로구 순으로 많음
data_result['CCTV비율'] = data_result['소계']/data_result['인구수']*100
data_result['CCTV비율'].sort_values().plot(kind='barh',grid=True,figsize=(8,8))
plt.show()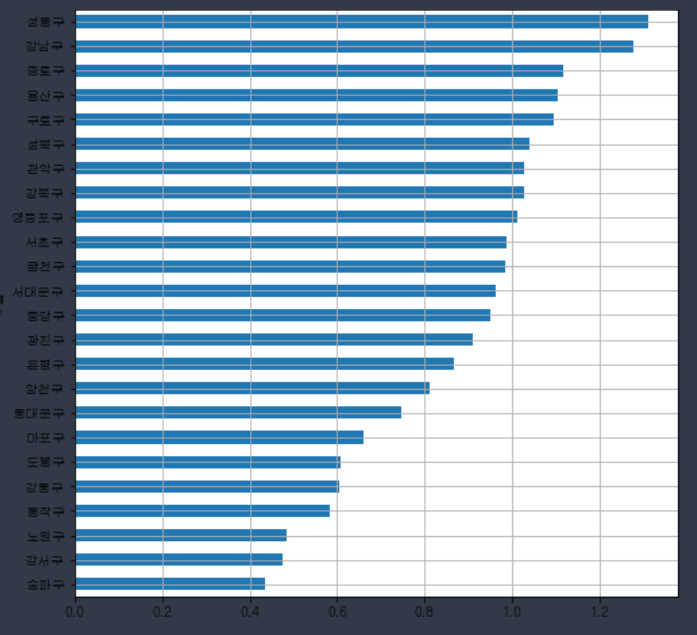
>> '구'별 인구수 대비 CCTV 개수의 비율을 살펴보면 성동구 > 강남구 > 종로구 순으로 많음
plt.figure(figsize=(8,8))
plt.scatter(data_result['인구수'],data_result['소계'],s=50)
plt.plot(fx, f1(fx), ls = 'dashed', lw=3, color='g')
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()
>> 인구수당 CCTV 개수의 산점도 그래프
fp1 = np.polyfit(data_result['인구수'], data_result['소계'],1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)
data_result['오차'] = np.abs(data_result['소계'] - f1(data_result['인구수']))
df_sort = data_result.sort_values(by='오차', ascending=False)
df_sort.head()
fp1 = np.polyfit( , , 1 ) : 1차식의 계수를 가지는 직선
>> array([4.19435402e-03, 1.70163777e+03])
>> 절편 : 4.19, 계수 : 1.7
f1 = np.poly1d(fp1) : polynomial(다항식) class를 만듦
>> poly1d([4.19435402e-03, 1.70163777e+03])
>> fp1으로 찾은 절편과 계수를 이용해 1차함수 만듦
>> 소계 = 4.19*인구수 + 1.7
fx = np.linspace(100000, 700000, 100) : start=100000, end=700000, 구간 내 숫자 개수 =100
>> 100000과 700000 사이에 균일한 간격으로 숫자 100개 >> 이 사이즈로 그래프 그림 (x축 데이터)
data_result['오차'] = np.abs(data_result['소계'] - f1(data_result['인구수']))
: 오차 = |소계-(f1_소계 = 4.19*인구수 + 1.7)|
>> 오차 = 초록색 직선과 각 구별 실제 CCTV 소계와의 차이
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'], data_result['소계'],
c=data_result['오차'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
for n in range(10):
plt.text(df_sort['인구수'][n]*1.02, df_sort['소계'][n]*0.98,
df_sort.index[n], fontsize=15)
plt.xlabel('인구수')
plt.ylabel('인구당비율')
plt.colorbar()
plt.grid()
plt.show()
plt.scater(x,y, s=area, c=colors)
>> 인구수를 x, 소계를 y로하고 마커를 '오차'로 나타내는 산점도
plt.plot(x,y,ls,lw,color)
>> fx를 x, f1(fx)를 y, linestyle='dashed', linewidth=3, color=green
>> fx 간격으로 1차함수 f1을 그리는 것
for n in range(10):
plt.text()
>> data_result그래프를 오차를 기준으로 내림차순 했을 때 10위까지를 불러옴
>> 텍스트 스타일을 설정
>> 1.02, 0.98 : 옆으로 이동. 이게 없으면 글자가 그림을 가림..